LLM Inference Series
LLM Inference Series--Introduction
LLM Inference Series--The two-phase process behind LLMs’ responses
At this stage, we have to introduce the more general key concept of arithmetic intensity a useful mental model called the roofline model and to link them to both key hardware characteristics like peak FLOPS and memory-bandwidth and to key performance metrics like latency, throughput and cost.
The two-phase process behind LLMs’ responses
You will in particular learn about the two phases of text generation: the initiation phase and the generation (or decoding) phase.
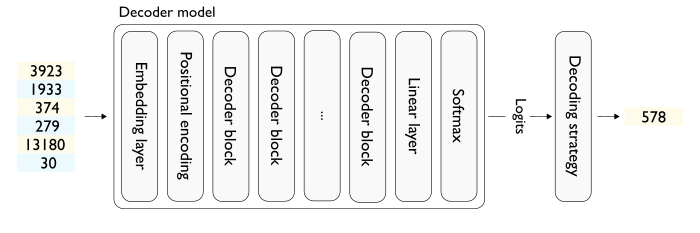
一个样例
Let’s assume that we process a single sequence at a time (i.e. batch size is 1)
Notice that the decoder itself does not output tokens but logits (as many as the vocabulary size).